Why Agents' Last Exam
3 min readThe Benchmarks Keep Falling.
The Economy Hasn't Noticed.
AI progress is shaped by what we choose to measure. We are building the instrument that measures what matters.
AI has beaten world champions at chess and Go, passed the bar exam, and reached gold medal level on math olympiads. The benchmarks keep falling. And yet, measured by the yardstick that ultimately matters (economic output) the impact has been surprisingly muted. Despite over $300 billion in global AI investment in 2024 alone (Goldman Sachs Research), U.S. labor productivity growth in 2024 came in at roughly 2.2%, a pace nearly identical to the pre-ChatGPT baseline.
McKinsey's 2024 Global AI Survey found that fewer than 1% of companies have deployed AI at scale across their core operations. Goldman Sachs analysts themselves, in a widely circulated 2024 note titled “Gen AI: Too Much Spend, Too Little Benefit?”, questioned whether the technology would ever deliver the transformative gains its proponents promised. The gap between benchmark performance and real-world value creation is not a rounding error. It is the defining tension of this moment in AI.
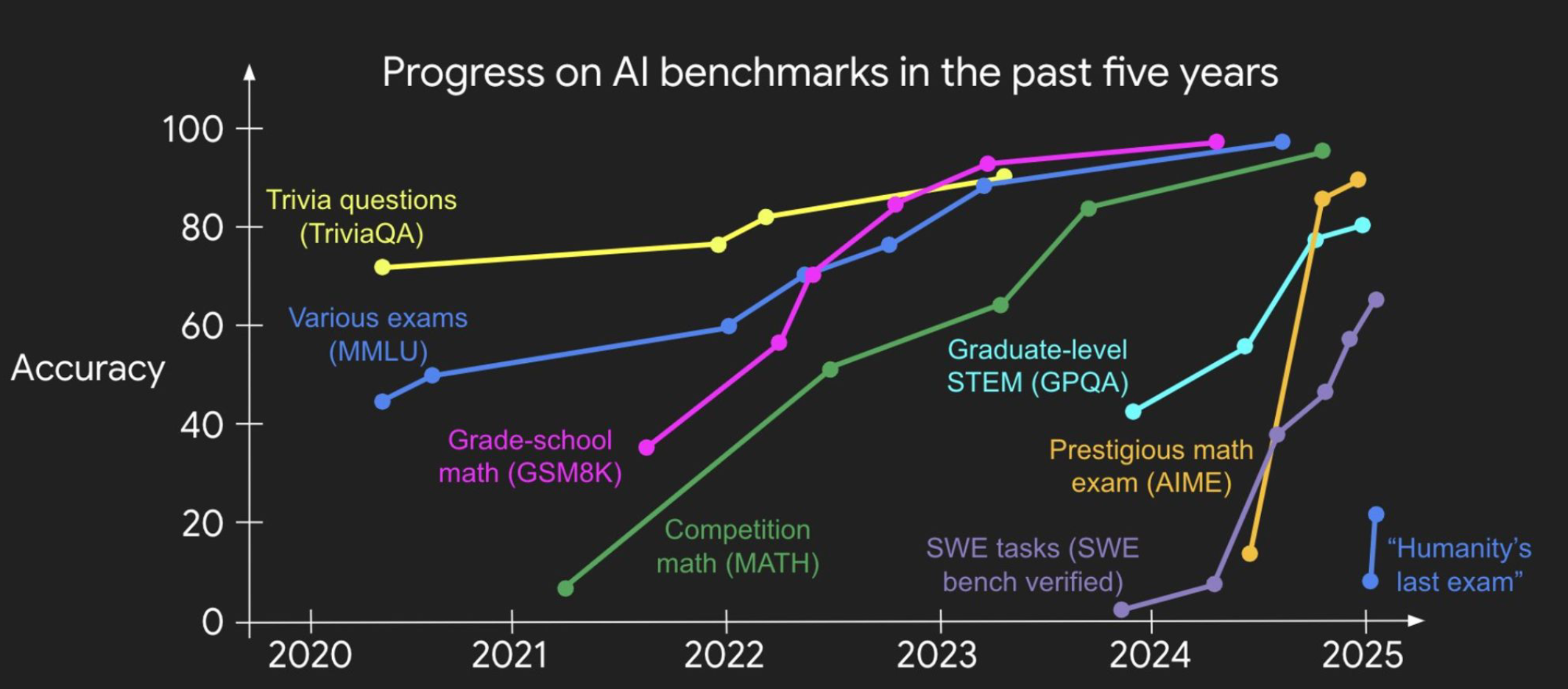
“We should fundamentally re-think evaluation. AI has beat world champions at chess and Go, surpassed most humans on SAT and bar exams, and reached gold medal level on IOI and IMO. But the world hasn't changed much, at least judged by economics and GDP. I call this the utility problem, and deem it the most important problem for AI.”
Progress Is Driven by Benchmarks
The history of AI is largely a history of benchmarks. ImageNet unlocked a decade of advances in computer vision. SWE-bench turned software engineering into a quantifiable, improvable discipline, and not coincidentally coding is now the one domain where AI has genuinely restructured how professionals work.
In finance, healthcare, legal, engineering, and manufacturing, the industries that collectively account for the vast majority of global GDP, and nothing equivalent exists. Most agent benchmarks focus on one to four domains, run short-horizon tasks in simplified environments, and score outputs with LLM judges rather than objective criteria. The benchmarks that do take economic value seriously, such as GDPval and the Remote Labor Index, rely on human expert evaluation, making them expensive and hard to reproduce at scale.
The field faces a fundamental trade-off: benchmarks that are easy to run are not economically meaningful, and the ones that are economically meaningful are not easy to run.
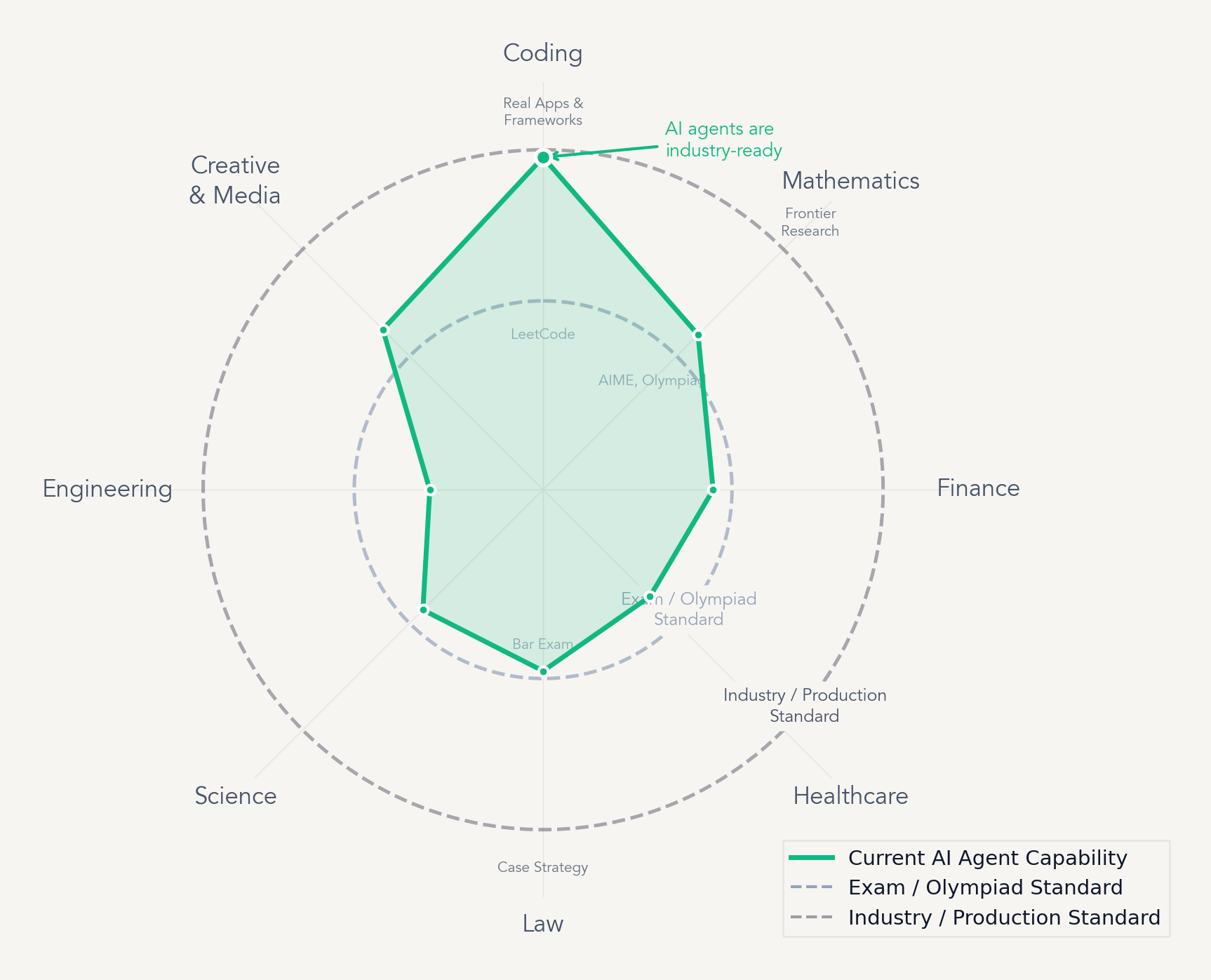
Agents' Last Exam Resolves the Trade-off
Agents' Last Exam is designed to resolve that trade-off directly. Every task is drawn from a real professional workflow, executed inside the environments practitioners actually use, and scored against objectively verifiable outcomes rather than proxy metrics.
The long-term goal is not merely to create a harder leaderboard. It is to build an instrument that faithfully tracks whether AI is delivering economic value at the industry level.
If Agents' Last Exam reaches saturation by 2028 or 2030, it will not mean that models got smarter in a lab. It will mean that AI agents are doing the work that financial analysts, radiologists, structural engineers, and supply chain managers do today, as fluently and naturally as AI-assisted coding has already become second nature to a generation of developers. A benchmark saturated is an industry transformed.
Help us build the benchmark that closes the gap.
Contribute a Workflow →