Agents' Last Exam
Challenge and measure AI agents on economically valuable and real-world tasks.
Agents' Last Exam aims to build the largest-scale, broadest-coverage agent evaluation benchmark to date, measuring performance on long-horizon, economically valuable tasks with verifiable outcomes. Led by Berkeley RDI and 300+ industry experts, it now spans all 55 targeted sub-industries covering most major fields of professional work performed on a computer, with 1,500+ tasks collected toward a 5,000-task target, keeping scores objective, comparable, and meaningful across domains.
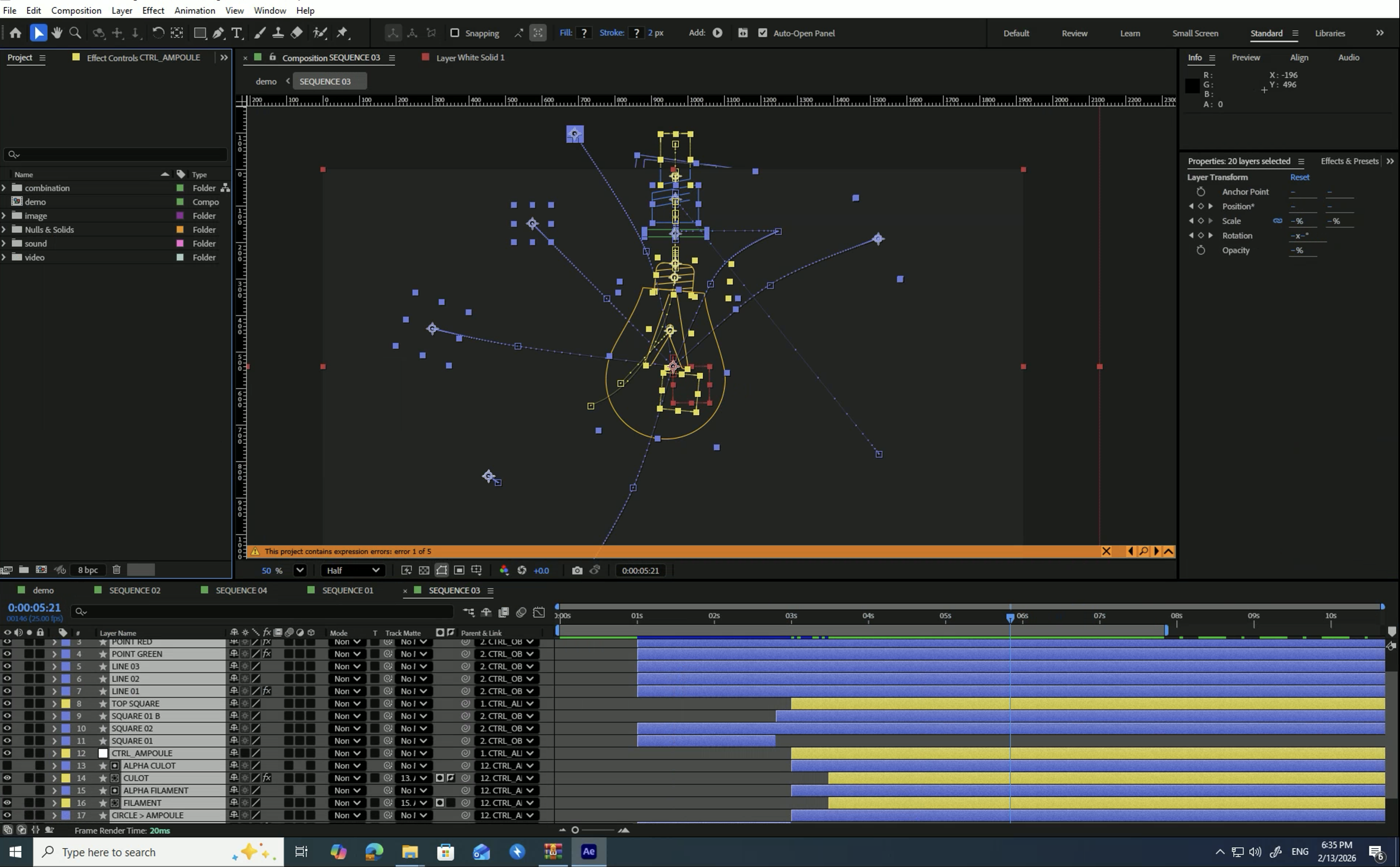
Motion & VFX
Agents complete animation and visual effects production tasks in Adobe After Effects.
Animation
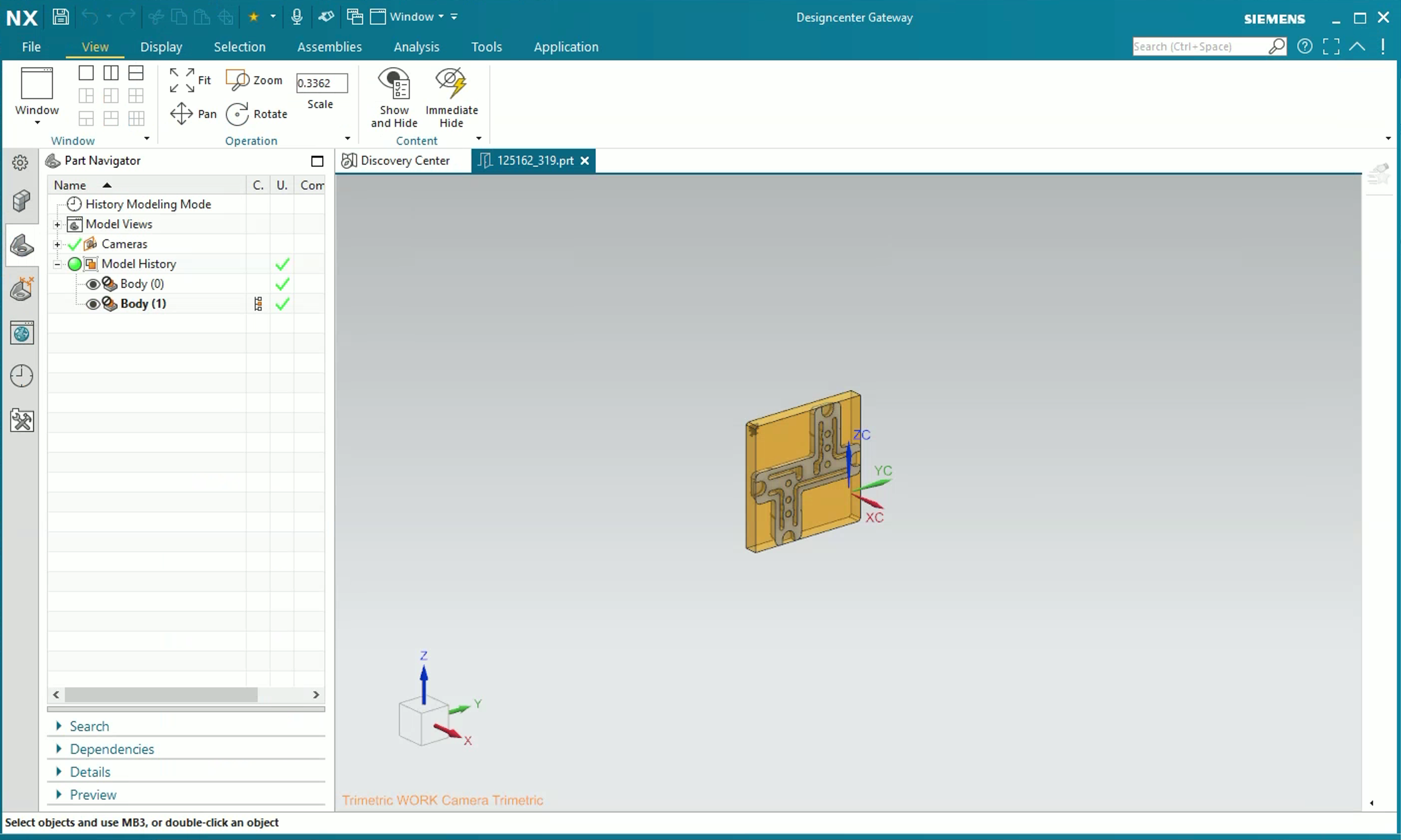
3D Modeling
Agents perform 3D model creation and editing tasks in Siemens NX.
Engineering
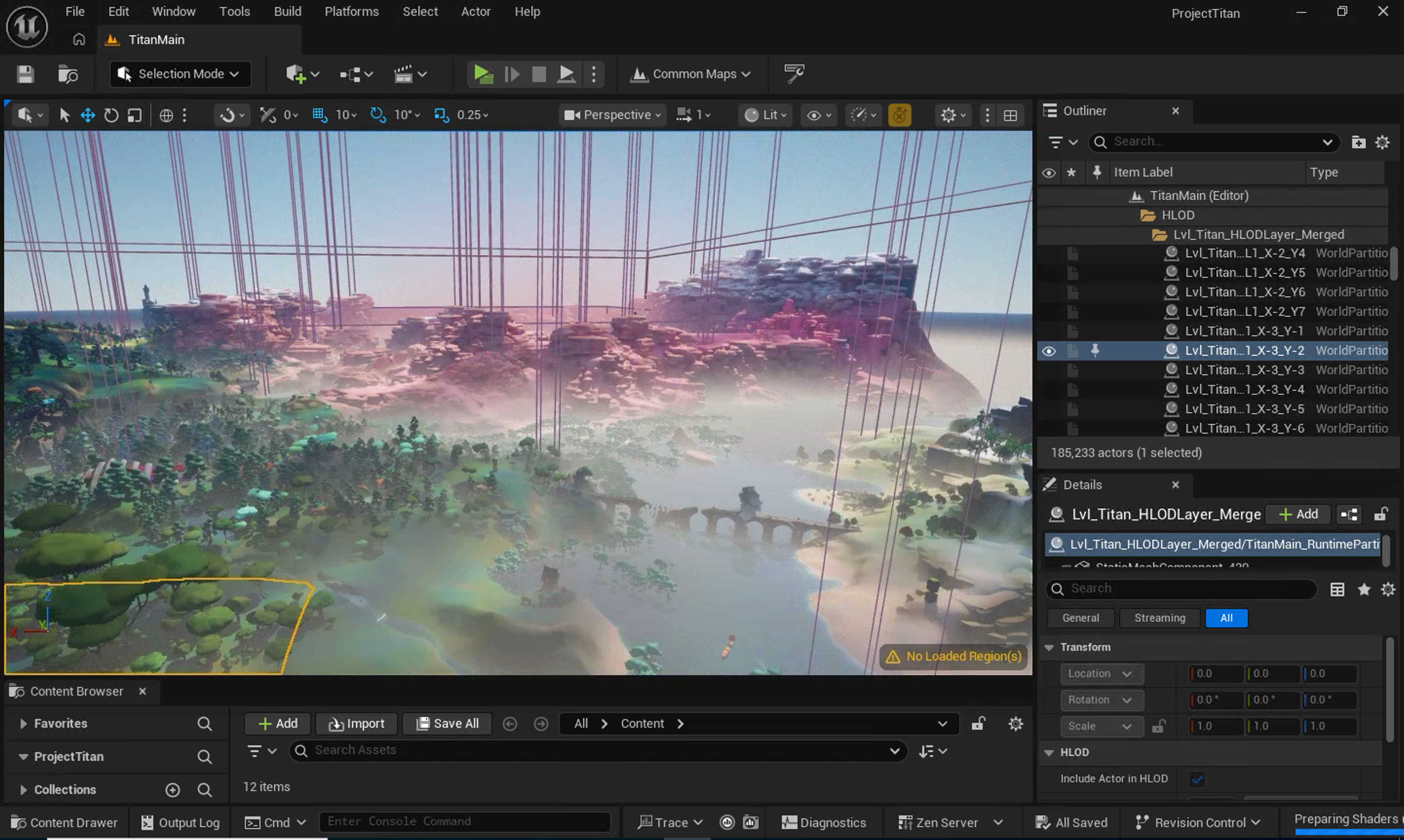
Game Development
Scene setup, asset placement, and rendering tasks in Unreal Engine.
Game Dev
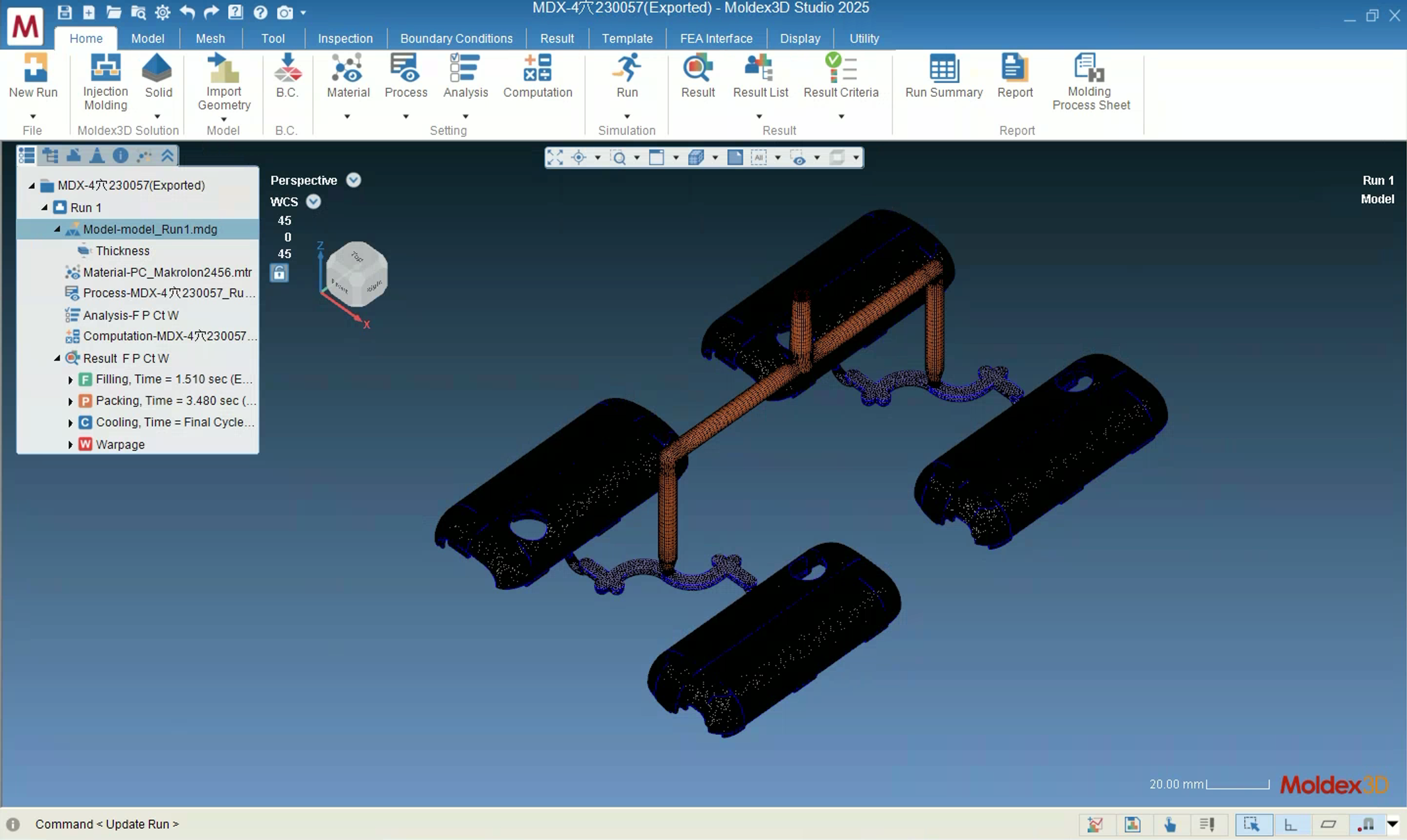
Mold Flow Analysis
Simulation and mold flow analysis tasks in Moldex3D manufacturing software.
Manufacturing
Architectural Modeling
3D modeling and energy analysis workflows in Rhino 3D for urban design in Zurich.
Architecture
Brain Imaging
Neuroimaging analysis and brain structure segmentation tasks in FSLeyes.
Neuroscience
Motion & VFX
Agents complete animation and visual effects production tasks in Adobe After Effects.
Animation
3D Modeling
Agents perform 3D model creation and editing tasks in Siemens NX.
Engineering
Game Development
Scene setup, asset placement, and rendering tasks in Unreal Engine.
Game Dev
Mold Flow Analysis
Simulation and mold flow analysis tasks in Moldex3D manufacturing software.
Manufacturing
Architectural Modeling
3D modeling and energy analysis workflows in Rhino 3D for urban design in Zurich.
Architecture
Brain Imaging
Neuroimaging analysis and brain structure segmentation tasks in FSLeyes.
Neuroscience
Motion & VFX
Agents complete animation and visual effects production tasks in Adobe After Effects.
Animation
3D Modeling
Agents perform 3D model creation and editing tasks in Siemens NX.
Engineering
Game Development
Scene setup, asset placement, and rendering tasks in Unreal Engine.
Game Dev
Mold Flow Analysis
Simulation and mold flow analysis tasks in Moldex3D manufacturing software.
Manufacturing
Architectural Modeling
3D modeling and energy analysis workflows in Rhino 3D for urban design in Zurich.
Architecture
Brain Imaging
Neuroimaging analysis and brain structure segmentation tasks in FSLeyes.
Neuroscience
Motion & VFX
Agents complete animation and visual effects production tasks in Adobe After Effects.
Animation
3D Modeling
Agents perform 3D model creation and editing tasks in Siemens NX.
Engineering
Game Development
Scene setup, asset placement, and rendering tasks in Unreal Engine.
Game Dev
Mold Flow Analysis
Simulation and mold flow analysis tasks in Moldex3D manufacturing software.
Manufacturing
Architectural Modeling
3D modeling and energy analysis workflows in Rhino 3D for urban design in Zurich.
Architecture
Brain Imaging
Neuroimaging analysis and brain structure segmentation tasks in FSLeyes.
Neuroscience
Motion & VFX
3D Modeling
Game Development
Mold Flow Analysis
Architectural Modeling
Brain Imaging
What makes Agents' Last Exam different
55
Sub-Industries Covered
1.5K+
Tasks Collected
300+
Experts

Co-led by
 ×
×
Contributors & Partners from
Academic Institutions
 MIT
MIT Harvard
Harvard Stanford
Stanford UC Berkeley
UC Berkeley Oxford
Oxford CMU
CMU Caltech
Caltech ETH Zurich
ETH Zurich Yale
Yale Columbia
Columbia UPenn
UPenn Cornell
Cornell Brown
Brown Johns Hopkins
Johns Hopkins NIH
NIH UCLA
UCLA UCSF
UCSF NYU
NYU U Michigan
U Michigan U Washington
U Washington Georgia Tech
Georgia Tech USC
USC UIUC
UIUC WashU
WashU U Melbourne
U Melbourne UC San Diego
UC San Diego UC Santa Barbara
UC Santa Barbara UC Irvine
UC Irvine UW-Madison
UW-Madison Emory
Emory UNC
UNC McGill
McGill U Waterloo
U Waterloo Boston University
Boston University U Helsinki
U Helsinki Monash
Monash U Colorado
U Colorado UC Santa Cruz
UC Santa Cruz UC Riverside
UC Riverside Northeastern
Northeastern Syracuse
Syracuse Lehigh
Lehigh UT Southwestern
UT Southwestern Texas A&MMITHarvardStanfordUC BerkeleyOxfordCMUCaltechETH ZurichYaleColumbiaUPennCornellBrownJohns HopkinsNIHUCLAUCSFNYUU MichiganU WashingtonGeorgia TechUSCUIUCWashUU MelbourneUC San DiegoUC Santa BarbaraUC IrvineUW-MadisonEmoryUNCMcGillU WaterlooBoston UniversityU HelsinkiMonashU ColoradoUC Santa CruzUC RiversideNortheasternSyracuseLehighUT SouthwesternTexas A&M
Texas A&MMITHarvardStanfordUC BerkeleyOxfordCMUCaltechETH ZurichYaleColumbiaUPennCornellBrownJohns HopkinsNIHUCLAUCSFNYUU MichiganU WashingtonGeorgia TechUSCUIUCWashUU MelbourneUC San DiegoUC Santa BarbaraUC IrvineUW-MadisonEmoryUNCMcGillU WaterlooBoston UniversityU HelsinkiMonashU ColoradoUC Santa CruzUC RiversideNortheasternSyracuseLehighUT SouthwesternTexas A&MIndustries
 Goldman Sachs
Goldman Sachs JPMorgan
JPMorgan Morgan Stanley
Morgan Stanley PIMCO
PIMCO Meta
Meta Amazon
Amazon Adobe
Adobe Oracle
Oracle Hippocratic AI
Hippocratic AI HubSpot
HubSpot Brix
Brix Photon Fund
Photon Fund Snorkel AI
Snorkel AI Goldman SachsJPMorganMorgan StanleyPIMCOMetaAmazonAdobeOracleHippocratic AIHubSpotBrixPhoton FundSnorkel AI
Goldman SachsJPMorganMorgan StanleyPIMCOMetaAmazonAdobeOracleHippocratic AIHubSpotBrixPhoton FundSnorkel AIAdvisory Committee













Why Contribute - Help Set the Standard for
Agent Evaluation in Your Industry
Shape evaluation standards, publish research, and earn recognition.
Insight into Agents in Industry
See exactly how AI agents handle real workflows in industry, and where they fall short.
Learn more →Co-authorship on Manuscript
Qualifying contributors receive co-authorship credit on the research publication.
Learn more →Monetary Awards
High-impact contributions are recognized with monetary awards from our $100K+ funding pool.
Learn more →For Domain Experts
Contribute domain expertise and real workflow data - no coding required.
For Researchers & Engineers
Turn real workflows into challenging, reproducible agent benchmarks: setup, execution, and evaluation.
FAQ
Common questions about software access, authorship, venues, and timeline.
FAQ page →Contact
For inquiries, reach out to the team directly.
rdi_research@berkeley.edu →Stay Updated
Subscribe for announcements, benchmark releases, and updates.
Join mailing list →